
Eskimo Snow and Scottish Rain*:
Legal Considerations of Schema Design
W3C Note 10 Sep 1999
- This version:
- http://www.w3.org/TR/1999/NOTE-md-policy-design-19990910.html
- Latest version:
- http://www.w3.org/TR/md-policy-design
- Previous version:
- http://cyber.law.harvard.edu/people/reagle/md-policy-design-19990206.html
- Author:
- Joseph Reagle,
Fellow Emeritus
<[email protected]>
Berkman Center for Internet and Society
Harvard Law School
Status of this Document
This document is a NOTE made available by W3C for discussion only. This
indicates no endorsement of its content, nor that W3C has had any editorial
control in its preparation, nor that W3C has, is, or will be allocating any
resources to the issues addressed by the NOTE. Publication of a W3C Note does
not imply endorsement by the W3C membership. A list of current W3C technical
reports and publications, including working drafts and notes, can be found at
http://www.w3.org/TR.
This is version 3.1 draft -- very stable -- of this paper. An
abstract of this paper has been included in the SSRN Electronic
Paper Collection. I thank Lawrence Lessig, Joel Reidenberg, Lorrie Faith Cranor, and Ralph Swick for their excellent comments and suggestions
that provided insight into concepts I had not understood well or had poorly
expressed. I also thank Rolf Nelson and
Robert Gellman for reading and providing comments that helped me improve the
flow and focus of this paper. Any weaknesses in the technical and legal
sections, or in the characterization of my reader's comments, are obviously my
own and may need correction. I welcome comments from other readers.
Examples that refer to P3P are based on the W3C Working Draft
9-November-1998. [*] A title borrowed from an email list subject
heading.
Copyright
© 1998 Joseph M. Reagle Jr. W3C liability,
trademark,
document
use and software
licensing rules apply. This document is best viewed with a W3C Stylesheet compliant application.
Outline
- Introduction
- Protocols, Syntax, and
Semantics
- Protocol Specification
- XML and Syntax
- XML Schema
and Few Semantics
- RDF and Some Semantics
- Applications and
Semantics
- Namespaces and URIs
- Summary of Syntax and
Semantics
- Schema Design
- Social Protocols
- Privacy Schema Design
- Political Consensus
in Schema Design
- Semantic Clarity
- The Danger
of Defaults in Schema Design
- Default Theory in
Law
- Conflicting Semantics
- Mandatory
and Optional Semantic Extensions
- Legal Understanding of
Contract Law
- Computers and Contract
Law
- Written and Explicit
Assent
- Mistake and
Impossibility
- Misunderstanding
Metadata Agreements
- Error in Syntax (Mistake of
Transmission)
- Error in Semantics
(Misunderstanding)
- Semantic
Discovery, Completeness, and Conflict
- The Hidden Drafter
- Breach and Liability
- Breach of Privacy
Agreement
- Conclusion
1. Introduction
Eskimos have many words for snow; Scots have numerous words related to
rain. This concept has achieved near urban myth status -- though it continues
to be contentious amongst linguists [Who40]. The idea is compelling because it
speaks to our belief that the mechanism of speech itself is a reflection or
our world and what we wish to say. Within this paper I examine the mechanisms
by which our computer agents will express and understand what we wish to say
in order to form online agreements.
This paper is about semantics. Semantics is generally defined as the study
of meaning. While the description seems vague, it is of immense importance to
the practical field of computer protocol design. For a computer program to be
useful, it needs to know what a token such as "reset" means. The process of
defining semantics within a specification (the document which details the
structure and operation of some technical design) is critical to the operation
of the protocol. How one defines -- or is permitted to define -- those
semantics can have an effect on the social context and purposes the protocol
serves.
My purpose is to examine the relationship between protocol design, policy,
and law in three parts. First, I focus on the definition of semantics within a
protocol and two metadata technologies (XML and RDF). This technical
introduction permits me to refer freely to the technical domain when I begin
my policy and legal analysis. Second, I look at the processes by which
metadata semantics are likely to be defined with respect to consensus,
conflict, and clarity. Finally, I review contract law as related to "the
unruliness of words," [KGK86] misunderstanding, and interpretation. Note, one
might answer two questions when addressing the validity of computer mediated
agreements: (1) computer agent competency and (2) the semantic clarity of the
agreement. This paper addresses the issue of semantic clarity; agent
competency and agency are addressed elsewhere. [Rea99]
A Note about this Paper
This paper is intended to be of interest to technical and non-technical
audiences alike who are interested in computer mediated agreements.
Specifically, where XML will be used in electronic commerce applications.
Readers familiar with issues of protocol and metadata
schema design may wish to skim up to §2. More
extensive, but accessible, explanations of the technical issues can be found
at [BC98, CKR98, Las98]. When terms are first introduced and defined they are
represented as below:
- Metadata
(statement, label)
- Data about data. Information that makes assertions or provides context
about other things.
- Schema
(vocabulary, rating system)
- The enumeration, structure and definition of the terms use to make
metadata assertions.
2 Protocols, Syntax, and
Semantics
This section describes how meaning is communicated through information
technologies.
2.1 Protocol Specification
The three critical parts of a protocol are syntax, semantics, and
state.
- Syntax
- The permitted arrangement or structure of letters and words in a
language as defined by a grammar.
For instance, the word "the" precedes a noun phrase. Computer
scientists do not limit themselves to English letters and words, but
refer to tokens and strings. For instance, a binary syntax permits for
zero or more occurrences of the tokens "0" or "1" -- in any order -- to
create a larger string.
- Semantics
- The meaning of a letters or words in a language, as opposed to the syntax which describes only how they are
arranged.
- State
- A modality of operation. For instance, a person climbing a ladder
passes through a number of states (steps). The term state machine is
often used to technically to describe the number of states and their
relation to each other within a protocol. For instance, a ladder may
have 5 states, and one must progress through a series of states to reach
the top.
Consider the traffic light as a very simple protocol. The tokens (letters)
in the traffic light protocol are green, red, and yellow. The syntax specifies
that yellow follows green, red follows yellow, and green follows red. Any
traffic light that permits a sequence of lights abusing this syntax is not a
proper traffic light.
In this example, the state machine is closely linked to our syntax. The
traffic light is in the red state, and is expressing the red "word." However,
the state machine of a traffic light has more than three states. For instance,
there are numerous states behind any red light. It may be counting down (like
someone descending a ladder) such that it will fall into the green state
within 1 minute. Or, it may be be counting up as the density of cars on the
perpendicular road increases. Given the clear specification of the traffic
light's syntax and state machine, a traffic lights can sit at an intersection
happily churning through its various states while emitting a series of
colorful words.
What is missing from my description? The semantics. It is only when the
semantics of words are imparted to the driver does the traffic light protocol
become useful. Green means go, yellow means caution, red means stop.
How do we create the protocol and ensure it works? Technical specifications
are written to describe the syntax, semantics, and state of a protocol.
Standards are developed to ensure independent parties can understand the
specification. This promotes interoperability, improves the total social
welfare of the community, and increases safety. For instance, a standardized
version of our traffic light protocol serves all three purposes. Wherever I go
in the US, my driving skill will interoperate with the traffic lights. Traffic
lights promote efficient road utilization (flow control), and help prevent
collisions. Those that abuse the protocol for their own benefit -- and to the
detriment of others -- are incompatible or non-compliant and may need to be
policed. Boston drivers are well known for running red lights -- I can only
hope they get tickets!
2.2 XML and Syntax
XML (eXtensible Markup Language) is a specification of the World Wide Web Consortium, the standards
organization for the Web. XML is a method by which users specify a syntax
for structuring Web documents, sometimes known as markup. (Think of an editor
"marking up" a manuscript with typographic annotations.) For instance, one can
use XML to specify that an HTML page has no more than one title, and that
after the title one can have any number of other elements within the body such
as headings, paragraphs, and links. Note, one might speak of syntax at a
number of different levels. XML enables users to create their own syntax for
structuring documents (e.g., one title, one body, with many headings and
paragraphs). To do this, XML itself specifies a syntax that (1) allows users
to express their own syntax and (2) constrain what users can do.
Why or how would users want their own structure? One might use markup
elements to represent legal citations on the Web. Consider the following:
ACLU v. Reno , 929
F.Supp. 824 (E.D. Pa. 1996)
The Bluebook provides syntax rules for constructing proper citations
to legal works. In this case, it tells us that the following terms must appear
in the following order with the proper abbreviation and formatting norms.
- the case name is ACLU
v. Reno;
- the published source is the West's Federal Supplement, volume 929 at
page 824;
- the court is the United States District Court of Eastern
Pennsylvania;
- the year of the decision is 1996.
One could represent this in XML as
<case URI="http://www.ciec.org/decision_PA/">
<title>ACLU v. Reno</title>
<volume>929</volume>
<source>F.Supp.</source>
<page>824</page>
<district>E.D. Pa.</district>
<year>1996</year>
</case>
Applications can then store, process or display this information in many
ways. Note, none of the key words like "title" or "volume" are defined by XML.
XML just profides for the syntax, users define the words. Another example is
that of using <book>, <title>, <author>,
and <summary> tags to structure a bibliographic entry.
<book condition="good">
<title>Eskimo Snow</title>
<author>Joseph Reagle</author>
<summary>Metadata design has
social
implications.</summary>
</book>
The key words between angle brackets are known as elements or tags,
information within an element are equated to each other and are known as
an attribute and value, and the text inside the
elements is the content:
<element
attribute="value">content</element>
2.2.1 XML, Few
Semantics, and Schema
The bibliographic example of XML also gives some indication of what role
the content "Eskimo Snow" or "Joseph Reagle" plays in the document. However,
it is extremely important to note that XML itself did not express semantics
(meaning). In our example, one gets meaning from the natural language text
within the tag. The following is an equally acceptable chunk of XML:
<field83>
<field52>Eskimo Snow</field52>
<field31>Joseph Reagle</field31>
<field35>Metadata design has
social
implications.</field35>
</field83>
The information is still structured, but the meaning of the tag is now
opaque and since it is not captured within the tag by natural language, it
needs to be explicitly declared elsewhere -- or possibly inferred from the
content itself.
If XML is the mechanism by which one defines a set of tags and their
relation to each other, how does one actually accomplish the task? Through a
"schema." A schema is the definition of the tags and
their relationships. Historically one accomplishes this with a schema
definition language. The Document Type Definition (DTD)
language describes the rules by which one defines the syntax of user created
tags. For instance, the following excerpt from a DTD states that bibliographic
entries must have one title, zero or more ("*") authors, and zero or one ("?")
summaries -- the summary is optional.
<!ELEMENT book (title, author*, summary?)>
The XML specification defines the permitted structures that DTDs may
generate. For instance, the XML specification states that no element (such as
title) may have two definitions, as this would lead to confusion.
We now know how to define schema, but why do we care? Because it
promotes syntactic
interoperability: any client can immediately understand the structure of an
arbitrary XML document. Even if my application never encountered a recipe
before, if it encounters a recipe schema in XML, it can process the recipe
structure, it will know that all recipes have ingredients without having to
ask the user to intervene or install anything!
2.3 RDF and Some Semantics
How then do we communicate meaning? It is wonderful for an XML application
to be able to know -- on the fly -- that all recipes have ingredients.
Wouldn't it be nice if it was able to figure out that barley malt is an
alternative ingredient to honey -- again without the user having to
intervene?
The Resource Description
Framework (RDF) [RDF99], another W3C Recommendation,
constrains the productions permitted by XML with a data model, and it defines
its own syntax (a special set of XML tags) so that the meaning of tag
relationships can be enriched.
There are three core concepts to RDF.
- A resource is an object out there on the Web. Objects are referenced or
located by a Uniform Resource Identifier (URI/URL). (The URI
"http://foo.com/homel" references an object: a home page.) RDF also
defines a number of containers, for grouping resources. The three
containers defined are bags (a list of unordered items), sequences (a list
of ordered items), and alternatives (only one of a set).
- A property is a characteristic, attribute, or relation used to describe
a resource.
- A statement is the application of a property (e.g. background color),
with a value (e.g. white), to a resource (e.g. my home page).
The RDF data model encapsulates all of these concepts so one has a way to
think about the relationships between resources, properties and values. The
way the data model is commonly portrayed is as a graph. Resources are ovals,
with arcs extending from the resource to a square. The arc is labeled with a
property, and the value within the square is its value. In this instance, the
homepage has a property of type creator, with a value of "Ora Lassila."
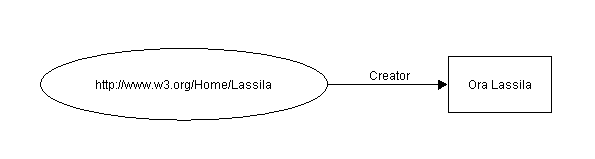
Consequently, through XML we have the ability to make sets of structured
information available to XML applications. Furthermore, one can use the RDF
data model (graphs) and syntax (special elements) to describe the
relationships between resources and elements. For instance, I could create an
RDF statement that said the book located at some URI has the characteristics
as expressed by my bibliographic example in the preceding section. Keep in
mind that RDF does not necessarily look different from XML. Rather, it
is XML, but with a particular data model and predefined set of
tags.
Note, RDF does not permit us to describe all semantics. Only some meaning
regarding the relationship of elements and resources, such as the things
within the container (<ALT> ... </ALT>) are
alternatives, or that one resource describes another. However, it doesn't
capture the semantics that are likely to be meaningful to an ordinary person.
It is useful for a computer to know the chunk of text "barley malt" is an
alternative type of "ingredient" to another chunk of text "honey." It
takes a human being that understands English to know the purpose of a recipe,
how ingredients fit in, what barley malt and honey are, how to get them, and
what they may cost. If I wanted the computer to cook me dinner, I'm likely to
get hungry.
2.4 Applications and
Semantics
Let us imagine a computer agent (application) that helps users shop for and
build a home computer based on the competitive prices of on-line stores
selling computer parts. The agent is familiar with the computer parts XML
schema. This schema specifies that every computer has a type of processor,
RAM, hardrive, and price. A human creator might program the agent to
understanding the meaning of price: that low values are better than high ones.
Perhaps she will use RDF so the application can explore different prices for
alternative components, or it will be able to check out reviews or statements
made by others on the Web about that computer retailer. The creator of the
agent also needs to program the agent on how to purchase things: if it decides
the price/performance is right, it should take the information from the
<purchase> element, invoke the checkbook application, and hand the
payment information to it. It is the creator of an application that associated
much of the meaningful semantics about the operation of the computer (make a
sound, save a file, invoke another application) with the processing of
data.
I've already described the benefits of syntactic interoperability: any
application can understand the structure of a document the first time it
encounters it. Semantic interoperability gives us more. It allows us to take
the semantics that associate invoking a payment application from a
<purchase> tag and understand and share that as well. Whereas no
one conceived of online grocery shopping, my agent might already be familiar
with recipes, as well as buying computer parts, there is no reason it can't
buy ingredients (recipe parts) on-line! The more meaning (how to agree, how to
invoke, how to buy) we capture in computer understandable schemas, the more
they will be able to help us. The authors of [CKR98] described this
characteristic well:
And yet the ability to combine resources that were developed
independently is an essential survival property of technology in a
distributed information system.... In his keynote address at Seybold San
Francisco [Berners-Lee, 1996], Tim Berners-Lee
called this powerful notion "intercreativity".
Presently, the most reasonable way to define operations and methods as part
of a schema is to rely upon Remote Procedure Calls, object oriented network
repositories, or computer languages like Java. How these might be best
integrated into syntax and other semantic definition languages is an ongoing
area of research.
2.5 Namespaces and URIs
The final issue in this brief technical exposition is that of name spaces.
As I already demonstrated in my description of RDF, the URI (Uniform Resource Identifier) is a way to identify
and locate a resource (object) on the Web. Namespaces [BHL99 ] address the
question of how to identify a schema, and how to mix various schema within one
document. They accomplish this by using a URI.
- A namespace is a globally unique identifier for a schema. Computer
agents could automatically fetch an XML/RDF schema definition and then
dynamically operate on information it encounters in that schema. Though
this agent behaviour is not required by the namespace specification it
will likely be a useful feature of future implementations.
- The namespace URI comes to be known as an identifier not only for the
schema definition, but the semantics that are associated with it. For
instance, if I want my application to not only understand payment
mechanisms, but to be able to invoke them, I may have to visit and install
a payment agent which is accessible at that URI. In the future, if I
encounter a XML/RDF of the same namespace, my agent will know to invoke
the same helper application.
Namespaces appear in XML as follows:
<book
xmlns:book='http://library.com/book/schema'
<book:title>Eskimo Snow</book:title>
<book:author>Joseph Reagle</book:author>
<book:summary>Schema design has
social
implications.</book:summary>
</book>
The prefix "book:" clearly signifies that a tag is defined by the book
schema at the URI provided. Why do we need to do that? It allows us to
represent the element and any semantics associated with it unambiguously.
Consider the case in which a different organization defines a schema for a
poetry book; they allow more than one title to appear within a book, since a
poetry book has many poems, each with its own title. Rather than requiring a
centralized registry for all elements, namespaces permit anyone to use any
element they want in their document, and to combine schemas, as long as they
qualify the element name. Note, schema designers should only use names that
include URIs under their administrative control. For instance, a third party
should never declare a namespace of the type "http://w3.org/bib.schema" if she
does not control the identified resource because it may be deleted or changed.
(See §3.4.2 for an example of why this is important.)
2.6 Summary of Syntax
and Semantics
Before proceeding to §3, where we learn about the policy implications
of schema design, I wish to reiterate a few key points.
- Syntax is how information is structured.
- Semantics is what information means.
- Schemas describe a particular syntax.
- Schemas are sometimes used to capture semantics as well. The semantics
might be expressed in a protocol specification, computer understandable
language, or a natural language description.
- Mechanisms for expressing syntax and machine understandable semantics
(schema definition languages) are being developed.
- The more syntax and semantics an agent can understand without human
intervention, the more powerful and flexible the agent becomes.
3. Schema Design
In Judeo-Christian theology the first power granted by its God to man was
the power to name, "Out of the ground the Lord God formed every beast of the
field and every bird of the air, and brought them to Adam to see what
he would call them. And whatever Adam called each living creature, that
was its name." (Gen2:19-20).
Designing a schema that others will use is -- in some sense -- an exercise of
the power to name.
This section examines the policy implications of schema design. When I
refer to "policy implications" I mean the substantive non-technical issues
related to the schema design process and its result. A substantive issue is
when a question is likely to be decided on the basis of something other than
technical merit, or if the answer to that question is likely to have an effect
on a non-technical domain. The non-technical domains obviously include legal,
political, social, and market concerns. While this section's example
application is that of privacy, the questions raised apply to the design of
commerce, intellectual property, or any other schemas that capture
relationships or are used to reach agreement.
3.1 Social Protocols
"Social protocol" is a term I use to discuss protocols (or applications)
that enable individuals and communities to express social capabilities. This
would include tools necessary for creating rich content, managing trust
relationships, conducting commerce, making verifiable assertions or
recommendations, and enabling agent assisted (or automatic) decision making.
The ability to make verifiable assertions, to build reputation, to solicit
advice, make agreements, and defer to a trusted source are all real world
capabilities. This is what real world relationships are built on. If we want
sophisticated cyberspace relationships, we will need similar mechanisms.
While I do not wish to spend too much time on the concept of social
protocols, (see [Rea98] for more background), the important factor for
analysis is the degree to which the semantics and operation of social
behavior/structure are captured within the data structures and protocol of
the application. This is critical because it is at this point that
social/legal concerns and methods have an undeniable effect on technical
design.
3.2 Privacy Schema Design
My example application of schema design will be privacy. Consider a
metadata schema that was designed to communicate natural language semantics of
a Web site's privacy practice (e.g., purpose of data collection, whom it is
redistributed to, etc.). This is one of the key components of the W3C's Platform for Privacy Preferences (P3P), its
Harmonized Vocabulary is just such a schema. I will examine issues related to
achieving (1) consensus in schema design and (2) semantic clarity in its
definition and implementation.
The intent of the P3P Harmonized Vocabulary is to express data collection
practices in a proposal such that it can be
acted or mediated on by the user's computer agent. The agent does not truly
understand the natural language semantics of "the purpose is for marketing
activities," but it can understand that the user told it to reject proposals
with purpose=4.
The goal of P3P is to enable users to operate within a sphere of policy of
her choosing without necessarily having to investigate the -- sometimes
confusing -- natural language privacy practices of every site she visits. For
instance, a user could configure her agent to permit the release of her zip
code, and remain otherwise anonymous, such that she can received
geographically customized services. Also, the user would configure the agent
such that when the agent encounters a site requesting personal information,
the site's privacy practices must be assured by a trusted third party, and
only then would the user be informed of the site's other practices and
prompted for the information. She can now browse the Web confidently because
she has an explicit agreement about the privacy practices of the site.
3.3 Political
Consensus in Schema Design
Anyone can design a schema. One merely defines it in a language (such as
DTD), places it on the Web (at some URI), and everyone else in the world can
now use it to structure his or her information. However, for a schema to be
widely used, it must offer benefits to its users.
While anyone can design or use as many schemas as they wish, schema
adoption certainly exhibits the same network effects and externalities of
other technologies such as the fax or VHS standard. If 90% of the world uses
one privacy schema, there is little incentive to use another. However, unlike
other technologies such as fax machines or VHS, there is little technological
lock in. It is technically trivial to change or adopt schemas. Syntactic interoperability ensures that
when a new schema comes along, one does not have to throw away one's old
applications or technology to understand the structure of the new
schema. For instance, applications based on XML are like a VCR
that could play VHS, beta, or any other format. Admittedly, there would still
be pressure to minimize the number of "video schema." However, the success of
a schema is likely to be based more on the merit of the schema design rather
than success derived solely from a first mover advantage, market dominance, or
technological lock in.
To rephrase the preceding paragraph: whereas many competitive schemas may
exist for a given application, not all are equal. This is obviously related to
the human cost of understanding and supporting other schema. (While open
metadata structures lessen this cost, it remains above zero.) Consequently,
parties will often be interested in standardizing on one schema when possible.
This is certainly the case of privacy disclosures, which carry a great deal of
natural language privacy semantics that are costly to communicate to users.
(Users that have to understand different -- and often inconsistent -- terms
and descriptions are not likely to truly understand the disclosures.)
Consequently, one is presented with a design scenario in which conflicting
parties know it is in their interest to standardize upon one schema, but
differ regarding what should be in that schema. I identify three classes of
tension:
- Overly simple or complex. The natural language semantics are too simple
or too numerous (overwhelming) to be useful or comprehensible to the user.
Methods of addressing this concern are partly addressed in [CR97].
- It expresses semantics counter to the interests of a party.
- It does not express semantics that would benefit the interests of a
party.
In the privacy domain, examples of (2) and (3) are readily available. One
can imagine a company that sells information to third parties shying away from
redistribution disclosures. One can imagine a privacy regulator wanting as
many disclosures as possible, particularly with respect to a service's
jurisdiction or compliance with a legal code.
However, it would be naive to assume that all users of information fall
into class (2), and all regulators fall into class (3). For example, the
organization TRUSTe has developed a Web
icon/seal that is used to indicate membership in TRUSTe.The presence of the
icon means that the privacy practices abide by TRUSTe guidelines. Originally,
the icons made a privacy disclosure: there was a different icon for
each of the three ways a company might distribute user data to other parties.
One of the alleged reasons TRUSTe moved away from three trust marks was that
it was not granular enough; companies felt they were lumped together with
companies that had very different practices. A second example is the concern
of regulators about the presence of some disclosures in P3P. These disclosures
are about practices that are not legally permitted in a given jurisdiction --
having the ability to express an action implies the right to do so. The
inclusion, exclusion, and definition of terms in a schema can be a highly
political exercise for all involved.
So how does one resolve the tension between the desire to standardize upon
contrary interests? The approach taken in the P3P Harmonized Vocabulary, and
one I recommend for other applications, is to try to standardize as much as
possible, but to be cognizant of reality: "No single rating system or schema
can satisfy the whole world unless the whole world is of the same opinion."
[Rea97] Efforts should be spent on developing a core set of schema definitions
that all parties can agree to. Competitive or supplementary schemas may
develop as a response to the core schema's inadequacies. For instance, a
different group could develop a competitive schema that in time supercedes the
first. Or, a group (perhaps the original one) may supplement the original
schema with disclosures that were not required or well understood at the time.
These multiple schema's can be easily intermixed using the XML-namespace facility.
Where consensus cannot be achieved, the environment of adoption and
deployment (individuals, markets, regulators) would be the ultimate judge of
which schema (or set of schema) is most appropriate -- I refer to this process
as the schema ecology. Again, the charter
states the group's philosophy: "... acknowledges that if two constituencies
disagree about X, they disagree. And if constituencies browse the Web space of
others, all of their unique concerns may not be addressed in that other space.
" [Rea97]
It has been observed that philosophy of seeking unanimity on a core set of
definitions can lead to minority veto power: that one party can easily keep a
particular disclosure from being included; this is true. The question a schema
design group is then presented with is, is this core schema at least good
enough to be acceptable as a minimum? Is the lack of a disclosure so important
that one cannot support a core schema without it? Only the consensus process
of a group can resolve this issue. However, the important result of this
section is that the consensus process need not be orientated towards reaching
the complete and exclusive solution. Rather, multiple schema can exist,
compete, and/or extend each other. When compared to the standardization of
other technologies, the adoption of a schema will be predicated more on its
merit than the brittleness of the technical or political institutions from
which it came.
3.4 Semantic Clarity
If one assumes complete consensus on the goal of a schema design, its
implementation and deployment may still lead to confusion. This confusion is
likely to result from a poor understanding of implicit (default) semantics or
a conflict of semantics within or between schema.
3.4.1 The
Danger of Defaults in Schema Design
Schema definition languages (such as DTD) allow one to define default
values for elements or attributes that are not present. For instance, the P3P
like statement below
<STATEMENT VOC:purpose="2,3" VOC:recipient="0"
VOC:identifiable="0" consequence="a site with clothes you'd appreciate.">
could be defined in a DTD such that if the "VOC:purpose" (purpose
of data collection) attribute is not included in the <STATEMENT>
element, the application should assume it's present but with a value of
"0." In P3P, a value of "0" means "Completion and Support of
Current Activity." One can also decline to set a default, in which case
the absence of an attribute means no semantic is expressed. This issue is also
subtly linked to the concept of, "that which is not stated, is not
done." For instance, in P3P, the specification defines the semantics of a
privacy statement such that the service is obligated to make representations
of all her privacy practices as they relate to Web interactions. A lack of the
statement is a representation that the corresponding action is not
done. Interestingly, there is a parallel to these concepts of defaults in
contract law, such as caveat emptor and Expressio
Unious Est Exclusio Alterius as discussed in §4.3.3.
Regardless, why would one use defaults? First, it permits brevity.
The terms that are most often used can be made the defaults, and need not
appear in the proposal. (Recall the proposal is the set of P3P data collection
and privacy statements.) Second, as originally formulated in P3P, it
compels the service to make a statement. A service can not turn a blind
eye to a disclosure they do not like, since its absence commits them to a
meaning regardless. If a service ignores the purpose attribute, a
misrepresentation that the purpose is only "Completion and Support of
Current Activity" could be fraudulent.
However, this leads to a rather interesting problem that I characterize
as syntactic interoperability with
semantic fault. A service, with many purposes, might not understand P3P
very well, and may assume the purpose declaration is optional. If the service
does not include the purpose attribute, the user is more likely to release
information since the purpose seems benign. While the protocol and syntax
give no indication that there has been a protocol failure the user gave out
information she should not have! I generalize this observation to state unlike
other failures, semantic faults are not readily manifested but have
substantive impacts on the user.
If one can assume ordinality, (that a purpose of 5 is worse than 4 with
respect to privacy), one can pursue a different approach: the default values
should be high. This means that the default value of purpose would be
5:other purposes. This still results in services having to counter the
implicit semantic, but a failure to do so doesn't harm the user, since
information is less likely to be released. If one can not assume ordinality,
one could make the default be that all values (1-5) apply, but the DTD syntax
does not permit such a default definition given P3P's present design.
The final strategy was to keep semantic requirements separate from syntax
requirements. This means that one should not use the meaning of a default
value to require a service to abide by the syntactic requirement that a
attribute must be present in the statement. If the purpose attribute is
required (syntax), it is defined as such in the DTD. It is up to the XML
application to enforce this requirement by rejecting any markup that lacks the
attribute.
3.4.1.1 Default Theory in
Law
It is interesting to note that this technical discussion of how to
structure default corresponds to the legal theory of default rules in
contracts. The traditional legal approach is to define the default term of a
contract -- if it is not explicitly defined -- as that which a majority of
those that make contracts would want. This is akin to the technical goal of
brevity and compact proposals!
Ayers and Gertner promote a different idea, one very similar to the idea of
defining a default such that a service is obligated to explicitly counter it,
"Penalty defaults are designed to give at least one party ... an incentive to
contract around the default rule and therefore to choose affirmatively the
contract provision they prefer." [AG, p. 91] However, while this may lead to
the efficient establishment of contracts because it forces information to be
revealed, it does not help in our example. The possible use of default rules
in P3P compels the disclosure of a predefined semantic, not information that
is likely to be novel or unique to the circumstance as does the legal
default.
3.4.2 Conflicting Semantics
In American culture -- at least -- there is an odd convention, particularly
among children and politicians, whereby someone can negate the meaning of
their statement by crossing their fingers behind their back. Can one do the
same with metadata? They can try. I've already recommended that when consensus
cannot be reached competing or supplementary schema might develop. Consider
four scenarios that might result:
- What happens if someone were to use a competing schema that had its own
purpose attribute and values? It would have a different name space. The
semantics of that name space would be different than those of the P3P
namespace, which includes "w3.org" in its
URI. An application must not assume any similarity between the two.
- What happens if a seperate regulatory jurisdiction schema evolved, such
that there was a jurisdiction attribute with ISO country codes
for values? That too would have its own name space, and it clearly does
not conflict with any of the semantics within P3P. Furthermore, Europeans
could require that all European Web services include that attribute within
their P3P proposals. This raises the issue that the very act of not
using a particular schema may lead to inferred semantics For instance, if I
went to a site that did not have the European disclosure, I'd know it
wasn't a European site and could configure my agent accordingly!
- Now, what happens if a third party creates a schema with an attribute
P3P_change_our_mind. The presence of this attribute with a value
of 1 means that the service reserves the right to change the
expressed policies of the P3P proposal at their pleasure. This in fact
tries to redefine the semantics of the P3P schema. Has the site now
relieved itself of an obligation to abide by the terms of a P3P proposal?
Not to a P3P application. A P3P application is only obligated to
understand the semantics of the P3P specification and schema.
- What if the W3C feels the recipient disclosure within P3P is somewhat
awkward and may need revisiting, how can the creators of P3P change it?
Such a change would require the issuance of P3P2.0, with its own namespace
and semantics. Since the technology is based on XML and RDF, and the
various schema are clearly distinguished within P3P, this would not be a
difficult task, however it is worthwhile to note that this instance is not
different from that of scenario 1. A P3P1.0 application has no obligation
to understand a P3P2.0 proposal. Though if it chose to do so, the
migration path would be an easy one.
3.4.3 Mandatory and Optional
Semantic Extensions
To finish this section, it is worthwhile to examine how a different
metadata technology, the Platform for Internet
Content Selections [PICS96], addressed issues of
semantic clarity and conflict -- we will return to this topic in the legal
context of §4.3.3. PICS, like RDF, allows one to associate a label
(metadata), in a rating system (schema) with a Web resource. PICS includes
mechanisms for stating two other things:
- There are no relevant semantics outside of this statement; and
- If there are other semantics they may be either safely ignored if not
understood, or they are required and you should go no further if you don't
understand them.
The first mechanism is useful when more than one label (piece of metadata)
exists for any given resource within a single schema. For instance, a "thumbs
up" label in the Siskel_and_Ebert schema might apply to the whole Web site and
sit on the home page, a "thumbs down" label exists five mouse clicks away from
that home page. In this case, one would wish to say on the home page, that
while this "thumb's up" label applies to the whole site, a more specific and
appropriate label might exist elsewhere on the site, in which case the one on
the homepage should be ignored. PICS includes syntax for distinguishing
between a generic label (which can be qualified but not overridden) and a
default label (that can be overridden.) P3P solves the problem of ambiguous
semantics by requiring that an identifier for any proposals relevant to a URI
be presented to the agent when it accesses that URI. (This is the hash of the
proposal, propID). Consequently, there is no
ambiguity as to which metadata applies to any given URI. If two proposals
apply, two identifiers will be provided. If there are conflicts between the
proposals, it is up to the P3P agent to discover them and report an
error.
I've already spoken of the second mechanism, that of mandatory/optional
extensions. Earlier I posed an example of Europeans requiring services to use
a jurisdiction schema. How could they compel a European agent to be cognizant
of that schema when intermixed with a P3P proposal? While there are no
mechanisms for this in schema definition languages presently, there are
extension mechanisms in protocol design. For instance, within PICS the
extension mechanism can be optional or mandatory. One refers to an extension
by way of a URI. If an extension is qualified as mandatory, the client
must use the extension, otherwise it must reject the entire service.
This mechanism was used to extend the digital signing capability of PICS.
Consequently, one can create a label such that if users do not understand
digital signatures, one can tell them not to risk processing the labels at
all. I expect this capability will be extended to schema definition
languages.
4 Legal
Understanding of Contract Law
So far I have focussed on how meaning is captured within metadata. The goal
is to allow such information to be readily available to users or their
computer agents. The obvious question now, is what happens if there is some
confusion in the design, specification, or presentation of that data? (I am
not addressing the question of error in the agent, I shall largely assume a
perfect agent for the purposes of this paper.) To state the question more
directly, if users are going to reach agreements on the basis of metadata,
what happens when an agreement was based on a misunderstanding about the
meaning of the metadata?
Contract law enforces or binds parties to their agreements. It also
includes standards of resolving confusion related to ambiguous or
misunderstood terms, as well as providing default terms when they are not
present in the contract. Courts are called upon to determine whether a
contract is valid, and to whom the liability or risk in a dispute falls upon
through the enforcement of the clarified contract. I will examine the relevant
legal standards to shed light on how issues of confusion in schema design will
likely be met by law. My goal is not to review all of contract law, but to
call out salient points that will be notable when applied to computer mediated
agreements.
How is a contract made? The process of forming an agreement is
straightforward: there is an offer, consideration, and an acceptance
(manifestation of assent). The necessary ingredients to this process are two
or more parties, the capacity of those parties to reach agreement (resulting
from the competency to do so or because they are not otherwise precluded by
law), mutual assent based on some active consideration or other method of
validation, and an end agreement that is sufficiently definite. In
computer mediated interactions, these requirements seem to be easily met with
careful software design.
4.1 Computers and Contract
Law
Within this section I have the difficult task of introducing a wide body of
law that pertains to the legitimacy of on-line agreements while strenuously
attempting to limit the scope such that I can focus on issues relevant to
schema design. Consequently, I hope those unfamiliar with the law will be
satisfied with the brief introduction I provide, and I hope experts will
forgive my summary treatment of the concepts. My goal is not to argue that
computer contracts can or should be made, but largely assume they will be and
ask what things will technologists and lawyers need to pay particular
attention to in the design of metadata schema.
Contract law originated in common law, the accumulation of principles and
standards resulting from prior court decisions. This is different from a
legislative and statutory approach. US contract law is a hybrid of sorts. One
of the features of this hybridization is two institutions that harmonize court
decisions. The two institutions are NCCUSL's Uniform Commercial Code (UCC), which drafts laws that are then adopted by US states, and
ALI's Restatement, which derives its authority
from the soundness of its reasoning. These two texts are the basis of much
contract related teaching, analysis, and law.
Interestingly, it's the non-democratic nature of these institutions,
particularly the UCC, that has led to much of the protest regarding changes of
UCC Article 2b (the
Proposed Law on Software Transactions) with respect to online interactions.
UCC working groups are generally the provinces of legal experts, state
lawyers, and lobbeyists. Once an article is formulated and approved they are
often adopted by state legislatures with little subsequent discussion.
Advocates have protested that the crafting of UCC 2b has exceeded the
integration of current case law. Instead it creates new policy, biased by
special interests, and conducted in a closed forum. My inexpert opinion on the
topic is that much of UCC 2b is premature. Beyond the need to provide an
online equivalent of a signature and requirements for evidence, I believe the
novelty of cyberspace is being used to bypass principles and balances
associated with preexisting social policy and law that can and should
be applied to the online environment. These pre-existing principles are what
much of the following analysis is about.
4.1.1 Written and Explicit
Assent
Contract law has many dichotomous categories for contracts: written and
oral, express and implied, and enforceable and unenforceable. Since the
purpose of this paper is not to address whether computer mediated agreements
are of one type or the other, I shall quickly argue (and otherwise assume)
that because computer information is explicit it is more often on the left
side of the dichotomy (written, express, and enforceable) than not -- with the
following caveats.
First, computer information is similar to written information in that it is
recordable: logs can be saved and examined by third parties. This also leads
me to argue that a computer agreement is rarely implied. However, just because
information can be recorded does not mean that it will be recorded. The
persistence of metadata agreements and logs by the user's agent is dependent
on the agent's storage capacity -- which might be limited. A technical
and legal understanding needs to define the requirements for such
information to be used as evidence in disputes. These requirements would
likely include the format, timeliness, and security of the log file.
Second, the very purpose of metadata is to express information sufficient
for communicating some semantic to another party in a way that is
deterministic, persistent, and confirmable. However, while the terms of an
agreement are likely to be express, the assent of the agreement may not be --
depending on the design of the protocol. For instance, one can imagine a
protocol whereby assent is implied by further interaction with the service;
refusal is implied by stopping interactions with a service. For instance, P3P
combines both methods. Proposals are presented to an agent, which signals its
acceptance by sending an (OK) code and a propID (an identifier of
the proposal) with subsequent interactions. An agent need not signal
non-acceptance, it can simply discontinue the interaction.
Finally, there is enforceability: will a court uphold a contract? (This is
distinct from whether a contract is found to exist, or if it is voidable.) The
most common example of an unenforceable contract is when its scope is subject
to the Statute of Frauds. In such an instance, a court will not enforce a
valid contract for the exchange of goods if it did not meet the formalities
required by the Statute, such as the presence of a signature. Consequently,
while it is quite possible that subsequent interactions based on a metadata
proposal act as an assent to a valid contract, a court would not enforce the
contract without a signature. This is obviously the motivation for much of the
activity related to digital signatures.
Fortunately, I can narrow the scope of this analysis even further. Much of
contract law ("mistake" and "impossibility") concerns itself with issues that
are independent of the medium of expression. Namely, the effect of unforeseen
occurrences or changed circumstances that undercut the assumptions implicit to
a contract, neither of which are uniquely salient to metadata agreements.
4.1.2 Mistake and
Impossibility
A mistake is a belief about a fact at the
time the contract is made that turns out to be false. This does not relate
to predictions about the future (e.g., stock prices) but the facts of the
contract. For instance, if I was told John Smith was a good person, and I
entered into a contract with him, but later I learn it's the wrong John Smith!
I made a mistake. Impossibility is where an
assumption basic to the contract -- so basic it seems it need not even be
stated -- turns out to be false and makes the completion of the contract
impractical. For instance, if I was contracted to perform in a concert hall,
and the concert hall burns down, it's now impossible for me to perform
there.
Most online metadata assertions are likely to be about present day
circumstances or the characteristics of other resources, not quite as prone to
"contractual accidents" as agreements about the disposition of real world
goods over a long period of time. The seminal example of mistake is that of
the sale of a cow that was thought to be barren but became pregnant prior to
its shipment. (Sherwood v. Walker. 66 Mich. 568, 33 N.W. 919 (1887)
Regardless, when those issues of mistake and impossibility are relevant, they
are independent of the medium of expression and can be ignored for the
purposes of this paper. However, online mistakes will happen. Ralph Swick
points out that one such mistake might result from the revocation of
compromised cryptographic keys. Key revocation might not be known to all third
parties that might mistakenly enter into an agreement on the basis of a
compromised digital signature or certificate. Lorrie Faith Cranor points out
that a low level system administrator might not understand the privacy policy
of his company and make a mistake in crafting a P3P statement.
Within this paper my main focus is on the issue of how the data structure
design interacts with legal concepts of misunderstanding: where one or more parties to the
agreement did not properly understand the terms of the agreement; where the
contractual instrument did not cause a set of common semantics to be shared
between the parties.
4.2 Misunderstanding Metadata
Agreements
Again, the question here is not about the validity of the agreement because
of a characteristic of the computer agent, but because of the schema design
itself. Consequently, I will disregard the scenario where an agent acts
without the interaction with the user. In my example, the agent merely
presents information to the user based on a metadata statement. It makes no
decisions on its own.
Accordingly, let us assume a scenario in which a service used a metadata
statement to solicit information and describe the related privacy practices
and consequences (benefits) of that collection -- perhaps a free calander sent
in the mail. The user released information, but then realized someone made a
mistake. Someone was confused about the agreement because she is now getting
lots of junk mail. How, in contract law, does one challenge such an agreement,
and how is it likely to be settled? There are three basic problems that both
law and technology must confront:
- Semantics are ambiguous or misunderstood.
- Not all semantics are known.
- Semantics conflict.
I've already introduced the technical mechanisms of addressing some of
these problems in §2; I will now integrate those mechanisms into the
legal context.
4.2.1 Errors in Syntax (Mistake of
Transmission)
While I have said I shall largely avoid issues of mistake, an instance of a
mistake was where technology got its first introduction to contract law. The
seminal example is that of the telegraph. Imagine that an offer is sent for
one amount, but received as another. (Des Arc Oil Mill v. Western Union Tel.
Co., 132 Ark. 335, 201 S.W. 273, 6 A.L.R. 1081 (1918). In this example,
an error in the transmission mechanism caused a syntactical error, corrupting
both the structure and the consequent meaning of information. One can imagine
an equally likely scenario, where information transmitted over the Internet
becomes corrupted.
However, this scenario is not all that salient to schema design. It is
relevant to the network protocol design, but network services are certainly
capable of providing robust and high integrity information transport.
4.2.2 Errors in Semantics
(Misunderstanding)
Before information was ever sent over the Internet, meaning had to be
captured in a data structure. That metadata is then transmitted -- as
discussed -- and rendered to the user. At either end of the communication, in
the capture and reconstruction of meaning, there is room for error and
confusion. If a service states within a P3P proposal that it uses information
in identifiable form, and the graphical user interface (GUI) that presents
this information to the user is confusing, the medium has failed to properly
transmit meaning -- semantics!
Consequently, there are three areas where errors might be introduced in
the transmission of information. First, if the transport mechanism
of the Internet actually garbled the metadata on its way to the user, one has
a case of syntactical mistake resulting in semantic confusion. However,
this error is readily detectable (i.e., message authentication and integrity
checks). Second, in the case of confusion about a schema and its
representation, one has a more problematic scenario of semantic
misunderstanding. Recall that in §3.4.1 I said that in instances of
"syntactic interoperability with semantic fault"
errors are not readily manifested but have substantive impacts on the users.
If a semantic error arises from confusion, neither party may know of the error
until after the contract has been agreed to. Courts are then called upon to
interpret the contract and discover its true meaning. Third, the GUIs might
cause confusion indepdent of the schema design.
This later point of confusion introduced by the display mechanism is
sometimes characterized as a mistake of display. Fortunately, the legal
system has given thought to the presentation of contractual terms. The UCC had
defined what it means to be "conspicuous." [UCC §2-102(a)(7)] (See
[Efr97:1356] for analysis.) While I find their text to be purposefull naive
(e.g., all CAPS seems like a poor remedy) I would expect the presentation of
such terms on-line to be as open to review by an informed court as that of
printed text.
Consequently, if substantive terms are being negotiated through a GUI, GUI
designers will have to be very careful about how they present those terms.
Particularly if an agent encounters a schema it has never seen before -- as
they are liable to do as explained in section §2.5. In such a case, the
agent designer will not have had a chance to adjust the GUI to prominently
display the most relevant terms of that schema. Instead, schema designers will
likely have to provide hints in the schema design itself about which terms are
most important. Then, the GUI design does not then need to be familiar with
the semantics of every schema and design a custom interface, instead the
design can interpret and render the hints appropriately. In time, model
guidelines and experience in GUIs will advance such that we will have a better
understanding of what a reasonable GUI should look like for communicating
substantive terms. (Lessig comments that as our understanding of what a good
GUI looks like, so will our legal understanding of what is reasonably
comprehensible. This then influences the understanding of what types of
subjects and terms ought to be captured in such agreements.)
How might we remedy this problem of misunderstanding resulting from the
schema design or GUI ? Instead of relying purely on the presentation of the
metadata, users might be encouraged to print out and read the
complete natural language privacy practices of a Web site.
4.2.3 Semantic Discovery,
Completeness, and Conflict
Imagine one user makes a decision to accept a proposal on the basis of the
GUI presentation of the metadata, another user prints out the corresponding
natural language statement, and also makes a decision to accept the proposal.
Have both users agreed to the same thing?
A problem with privacy practices and shrink-wrap licenses today is that
they are essentially meaningless to the user. The text is so complex and
confusing users simply do not understand the terms, even if some are
capitalized. This is one of the problems metadata should be able to remedy, to
capture consistent semantics across services in a way that the user can use a
computer agent to assist them in understanding those terms and to act
accordingly. However, if one then says, you cannot rely upon the metadata
itself, but must print out and assent to the natural language description as
well -- or at least that is the user's obligation -- we have not solved the
problem! It may have made it more confusing!
I've presented a scenario where one questions where the "true" semantics of
an agreement reside. In §3.4.2 I also spent a fair amount of time
describing the technical issues associated with semantic conflicts. If more
than one statement exists they can extend or supplement each other, but what
if they conflict? Where does contract law stand on this question?
A key concept in contract law is that of the parol evidence rule. This rule
addresses the validity of past written or oral statements (parol evidence)
with subsequent statements. In general, it states that when parties form an
agreement in writing and express the fact that it is the final expression of
their agreement and that agreement is unambiguous, no parol evidence may be
submitted to supplement, explain, or contradict it. Where this expression of
finality is not present or where there is ambiguity that needs to be resolved,
consistent -- but not contradictory -- parol evidence may be examined to
supplement or explain those parts not completely expressed.
This type of concept (as discussed in §3.4.2) is extremely relevant to
metadata statements. Can one be assured that one has the complete set of
semantics before assenting? How would one negate previous semantics? Schema
and protocol designs must be very clear in addressing these questions. A
technical term often used in specifications is normative. Normative sections
and terms govern the exclusive and complete semantics of a specification.
Other parts of a specification might be useful in providing the purpose and
context of the specification, but they are not necessary. This other text is
similar to why the purposes of a contract are often explicitly spelled out --
all the "whereas" clauses. This other non-binding text provides additional
context to the comprehension of the normative sections.
P3P, as an application of metadata, was designed to directly address
questions of semantic discovery, ambiguity and conflict. However, it is not
unique. Resource discovery (finding all relevant semantics) and expiration
(when semantics are no longer valid) are central to protocol design. As stated
earlier, the P3P specification requires an agent to be notified of all
existing semantics (even if they are found in multiple proposals) by the
service. The service does this by sending a hash of proposals (propID)
that apply. If a service no longer wishes to operate under a past agreement,
it simply makes no solicitations, nor accepts any information, under that
propID.
In general, the best solution to problems of discovery and conflict is that
of forethought. Contracts that clearly state that they are the complete and
exclusive manifestation of the agreement (through a "merger" or "integration"
clause) are less prone to problems -- a feature metadata technologies are
readily capable of providing. P3P is defined as such at a number of levels.
The P3P specification requires the presentation of the propIDs by the service
to be the exclusive and complete set of semantics pertaining to the collection
of the specified information. This establishes the contract principle of
integration of all the terms of agreement into the propID. In addition, the
various data collection statements within a P3P proposal would be understood
in accordance with the judicial maxim for the interpretation of contracts:
"the enumeration some excludes others" (known to lawyers by the latin
expression: 'Expressio Unious Est Exclusio Alterius').
Basically, that which is not stated is not done. (If you do not say you
collect information, then you are not allowed to do so.) However, this
semantic is carefully qualified in that it applies to information related to
Web interactions and the data elements specified within the core
specification. A P3P proposal does not include the semantics of interactions a
user has with a service over different media, such as telephone or mail. (Joel
Reidenberg points out an interesting contrast to the Expressio
principle as applied to risk a user carries in an interaction.
Expressio promotes complete disclosure by a Web. The concept of
caveat emptor, "let the buyer beware", is a default rule of warranties
that allocates the risk resulting from a product's uncertain quality to the
buyer/user.)
As discussed in §2.5, the XML namespace mechanism can prevent semantic
conflicts in the schema definitions, such that one cannot confuse contrary
schema semantics -- one can supplement or extend. Conflicts between multiple
proposals, even when of the same schema, must be resolved by the application.
In law, this act is known as interpretation. In the short term, computer
agents will not likely be very sophisticated in their ability to interpret
multiple assertions to derive the complete set of semantics. Consequently, if
an agent believes there is any chance of confusion, it should reject the
proposals and inform the user.
Additionally, metadata technologies can easily represent if metadata is
final, complete, or if other terms are found elsewhere. In contract law, the
presence of a "merger" or "integration" clause is used to specify these
qualities of a contract. Communicating the completeness of a statement is the
purpose of mandatory/optional protocol extensions as described in PICS.
Also, it is trivial to reference other terms and semantics: to say, "You can
find other relevant terms at "http://www.foo.com/bar.html" because everything
appropriate would be on the net and referenced by a URI! However, while
pointing to other terms is not difficult, protocol designers are always
cognizant of the need to limit the amount of wandering a network application
needs to do to complete its task.
Finally, our scenario of using both metadata and natural language semantics
is problematic. However, as already stated, the comparison of a schema
definition and its application to the natural language expression is something
an informed person is capable of doing. Regardless, the P3P specification
states that the propIDs accompanying an interaction represent the
complete/integrated semantics of that interaction. A future email from a
service that states the terms of a past agreement have changed and allows the
user to opt-out of this change is not normative, meaning that a service that
acts on his revised view of the agreement is abusing the contract. For an
analysis of "the Battle of the Forms" outside the context of metadata
mechanisms see [Efr97:1328-1350]. Effross discusses the UCC's text on which
terms in differing versions of a contract are enforced or knocked out because
of (1) the role of the party, (2) the type of offer (i.e., offer to buy or
offer to sell) and (3) the requirements expressed for acceptance within the
contract itself (e.g., "a response to this offer of contract formation is an
express assent to the terms within this contract and no others.")
4.2.4 The Hidden Drafter
When courts interpret a contract they often look to what each party knew or
was likely to know (both themselves and of the other party); as well as
who drafted the terms of the contract. This analysis does not quite fit our
metadata scenarios. In the privacy application there are two other important
parties -- drafters of the contract if you will. The schema designer crafted
the terms used in the creation of agreement, and a GUI designer's product most
likely represented those terms to the user.
One need not know if the parties knew, or were likely to know, if a cow was
barren or not. Instead one must know if the either party properly understood
the GUI, that was predicated on the GUI designers understanding of the schema,
that was predicated on the clarity of the schema design!
For instance, the redistribution element of a privacy schema might permit
two values, (1) data is used only by the service, (2) data is
redistributed to third parties. A service that gives information to a shipping
company so as to fulfill a purchase order may consider this third party to be
an agent and will classify his redistribution practice as type (1). A user may
not share that understanding, and might be shocked to find that the shipping
company also used such data for their own marketing purposes! This very
example is probably one of the most difficult issues designers of the P3P
Harmonized Vocabulary had to address. One must avoid ambiguity while avoiding
schema so complex so as to be meaningless to the average user. How does one
resolve this? Be as specific as possible and take great care with the crafting
of the text. Otherwise, we will have to rely upon the consensus processes and
schema ecologies mentioned in §3.3 to
provide us the best designs possible.
How does one resolve semantic ambiguity introduced by these hidden drafters
of the contract? The only parallel in contract law that I can think of is the
law itself. Recall that the UCC defines contractual boilerplates and default
terms and conditions for others to use. If there is ambiguity in the UCC
itself, how is it resolved? Recall the UCC is implemented by the states.
Consequently, courts could be called on to rule on their reading of the laws,
legislators may clarify it through additional law, or the drafters of the UCC
may revisit the issue. The process in schema design is not that
different. The schema and GUI designers may be called upon to provide
the context for interpretation or provide a better design. (They might even be
held accountable for not providing a better design in the first place.)
4.3 Breach and Liability
Now, the difficult question! When the user starts getting junk mail and
sues the service for breach of contract because the shipping company used her
shipping information for marketing purposes, how will the court remedy the
situation?
I suspect a court would not find the situation all that novel. A court
would ask questions about the purpose of the interaction:
- Interpretation of the contract: which reading would the court make
itself based on the schema design, and parol evidence that complements the
agreement?
- The nature of the misunderstanding: if a court interpreted the contract
in favor of the service, it would still ask if the service knew that the
user would likely be confused. If so, the court is predisposed to favor
the "innocent" or naive user.
- Which party contracted for the the risk? In this case, it seems the
user enters into this transaction knowingly, putting her data at
risk, akin to the concept of caveat emptor.
- In the telegraph example in §4.2.1, the Court assigned
liability to the offeror of the contract by binding her to the party
responsible for the transmission (the telegraph operator). Hence
liability would fall on the service. (Des Arc Oil Mill v. Western
Union Tel. Co., 132 Ark. 335, 201 S.W. 273, 6 A.L.R. 1081 (1918)
- An approach favored by Prof. Murray [Mur90], is to assign liability
to the party which chose that media as the mechanism of reaching the
agreement. (Ayer v. Western Union Tel. Co., 79 Me. 493, 10 A. 495
(1887)). In our example, who chose the Web as the media for reaching
agreement? In the instance of negotiating for Web services, both
parties could arguably be said to have chosen that media.
- In our scenario of metadata and natural language versions of the
contract being available, the service could argue that if the
user did not choose to read the natural language description and
properly understand it, the user would bear the risk -- this is known
as the "flagellant" view. However, Restatement 211(3) places the
burden on the author to present the material clearly. In addition,
courts might also hold services responsible for ensuring the natural
language semantics do not conflict with those found in the metadata.
Consequently, if a user makes a decision on the basis of the metadata
only, and later finds that her understanding of the agreement was
abused on the justification that the natural language semantics were
different, I believe this could be reasonably adjudicated in the
user's favor.
see Restatement 211 (c)
Also, the court might ask questions about
- Is the contract enforceable: are the requirements of the Statute of
Fraud or other relevant laws met?
- Reasonable expectations of the contract: if a party was not likely to
read all the terms of a complex contract, did the terms meet the
reasonable expectations of what the contract actually said?
- The unconscionability of the contract: where the terms such that
"no man in his senses and not under delusion would make on the one hand,
and as no honest and fair man would accept on the other." (Hume v. United
States, 132 U.S. 406, 10 S. Ct. 134 (1889) quoting from Earl of
Chesterfield v. Janssen, 2 Ves. Sen. 125, 155, 28 Eng. Rep. 82, 100 (Ch.
1750)
In addition to interpreting terms and assigning them their normative
meaning, courts are also called upon to provide omitted terms. Consequently,
one approach to schema design is to be cognizant of this very fact. Wherever
there is likely to be confusion or contention in the definition of a term, a
buzzword such as "reasonable" may be inserted, which asks a future court to
apply its own semantic to the definition. This was encouraged by some involved
in the design of the P3P Harmonized Vocabulary, but was largely avoided when
possible. I believe it is the schema designer's obligation to be as definitive
as possible, and use subjective or relative standards lightly since the world
cannot wait for courts to rule before using the schema.
4.3.1 Breach of Privacy
Agreements
Finally -- while slightly out of scope -- I wish to address a pragmatic
question in the privacy example. If a court finds in favor of a user, did the
agreement provide them with adequate means of protection and remedy? Not
likely.
The present approach of contract law to remedy is one of economic
efficiency. The plaintiff should be compensated such that they are in a
position similar to the one they would've been in had the contract had not
been breached. (Restatement 2nd §347). Consequently, a breach of
contract is said to be efficient when the cost to perform exceeds the benefit
to both parties resulting from its performance. In such a case, the plaintiff
is compensated appropriately and the defendant decreases her costs.
What could be wrong with this? When one considers this rationale, the
relatively small value of exchanges in electronic commerce, the difficulty of
determining the expected damages (particularly in the privacy example), and
the transaction cost of resorting to a court for remedy, it is clear that it
will often be in the interest of a service to breach a contract. The rationale
of economic efficiency does not seem to act as a good disincentive against
breaking agreements when applied within the scope of most Web interactions.
However, there are a couple remedies. First, as part of the agreement, a
clause can define in advance the damages due in event of a breach (liquidated
damages). Second, legislatures and regulatory authorities may wish to
establish penalties such that parties are disincented to break agreements.
Unfortunately, neither of these approaches seem politically feasible in the
present day context of U.S. privacy protection, and in general seem counter to
the direction of present day policy on computer agreements. Consequently, the
rather weak remedies left to users are perhaps class action suits and public
pressure. For instance, Intel became the focus of recent attention because the
inclusion and default
activation of a unique identifier in every one of its new Pentium III
chips. This would be used to identify users in electronic commerce and other
net-based applications. Public pressure forced them to discontinue the default
activation of this feature.
Conclusion
Elsewhere [Rea99] I use a quote from the film The Princess Bride
to motivate an exploration of computer agents and legal agency:
"You
keep using that word, I do not think it means, what you think it means." I
was speaking of confusion resulting from a concept I define in this
paper, namely syntactic
interoperability with semantic fault. Protocol designers and
lawyers frequently use the term "agent" in the context of electronic commerce,
and while the syntax is correct, the semantics behind each usage does not
necessarily match. One needs to qualify each usage with a legal or technical
namespace!
Otherwise we end up with confusion. Without a clear definition of
semantics, we are not speaking of the same thing. If we are not speaking of
the same thing, the nature of our relationship is going to be less than
satisfactory. This applies as much to cyberspace as it does to real space. In
fact, cyberspace might have something to offer us that we don't have
otherwise: well-specified and explicit representations that our computers can
help us make sense of!
This is not to say there will never be confusion. There will be a confusion
while we gain experience in schema and user interface design, as we come to
understand what is feasible, fair, and beneficial to the conduct or our lives
online. This later process will be as political as it is technical. However, I
believe will be better served by this process of computer aided decision
making and schema design than its alternative. The subject of this paper
permits user choice, flexibility, and transparency in the context of common
law and contemporary judicial principles. The present day alternative is to
permit special interests to define a single set of terms, to set the defaults,
and to bias the standards of interpration and liability such that the user
always loses.
Bibliography
[AG] Ayres, Gertner.Filling Gaps in Incomplete Contracts: An Economic
Theory of Default Rules., Yale Law Journal Company. Yale Law
Journal, October, 1989, 99 Yale L.J. 87
[FOLDC] Denis Howe (ed.) FOLDC:
Computing Dictionary 1993, 1998. Links are provided to some technical
definitions by way of the Hypertext Webster
Gateway.
[Ber96] Tim Berners-Lee. Keynote
Address, Seybold San Francisco, February 1996. Available at http://www.w3.org/Talks/9602seybold/slide6.htm
[BC98] Tim Berners-Lee, Dan Connolly. Web Architecture: Extensible
Languages. W3C NOTE: 10 Februray 1998.
[CKR98] Dan Connolly, Rohit Khare, and Adam Rifkin. The
Evolution of Web Documents: The Ascent of XML, W3J special
Issue on XML, Vol 2, Number 4, Fall 1997, Pages 119-128
[CR97] Cranor and Reagle. "Designing
a Social Protocol: Lessons Learned from the Platform for Privacy Preferences
Project" Telecommunications
Policy Research Conference. Sept. 97.
[Efr97] Effross. "The Legal
Architecture of Virtual Stores: World Wide Web Sites and the Uniform
Commercial Code." San Diego Law Review. Vol 34, Number 3. Spring 1997.
[KGK86] Kessler, Gilmore, and Kronman. Contracts: Cases and Materials 984
(3d ed. 1986).
[Las98] Lassila, O. Introduction to RDF
Metadata. W3C NOTE: 13 November 1997.
[Mur90] J. E. Murray, Murray on Contracts § 38, at 92 (3d ed.
1990)
[BHL99] Tim Bray, Dave Hollander, Andrew Layman. Namespaces in XML
(14 January 1999). http://www.w3.org/TR/REC-xml-names
[PICS96] Miller J., Resnick P. and Singer D. PICS 1.1 Rating Services and
Rating Systems -- and Their Machine Readable Descriptions. (31 October
1996). http://www.w3.org/TR/REC-PICS-services
[RDF99] Lassila O., and Swick R. Resource
Description Framework (RDF) Model and Syntax Specification. (22
February 1999). http://www.w3.org/TR/REC-rdf-syntax/
[Rea97] Reagle, J. (Editor/Chair) Harmonized
Vocabulary Working Group Charter.
[Rea98] Reagle, J . Social Protocols:
An Introduction. Lecture Notes for The Law of Cyberspace -- Social
Protocols. Harvard Law School and MIT. September 1998.
[Rea99] Reagle, J . Agent:
I Don’t Think It Means, What You Think It Means. (19990524) LawTech'99.
[Who40] Whorf, B. L. (1940): 'Science and Linguistics', Technology
Review 42(6): 229-31, 247-8. Also in B. L. Whorf (1956):
Language, Thought and Reality (ed. J. B. Carroll). Cambridge, MA: MIT
Press. [While not explicitly characterized or analyzed within the reference,
this text, writings by Sapir, and resulting debate are the basis of a theory
now known as the Sapir-Whorf
hypothesis. This hypothesis posits that language affects the way we think.
Note, this is different -- though related -- to my more obvious generalization
that reality/context affects language. Also see the following URL on the
contention associated with "Eskimo Snow" : http://www.sfs.nphil.uni-tuebingen.de/linguist/issues/5/5-1239.html
]
Other References
Michigan Law Review, March, 1992, 90 Mich. L. Rev. 1145, 20448. Legal
Responses to Commercial Transactions Employing Novel Communications Media.,
John Robinson Thomas