D ISO 8601 Date and Time Formats
D.1 ISO 8601 Conventions
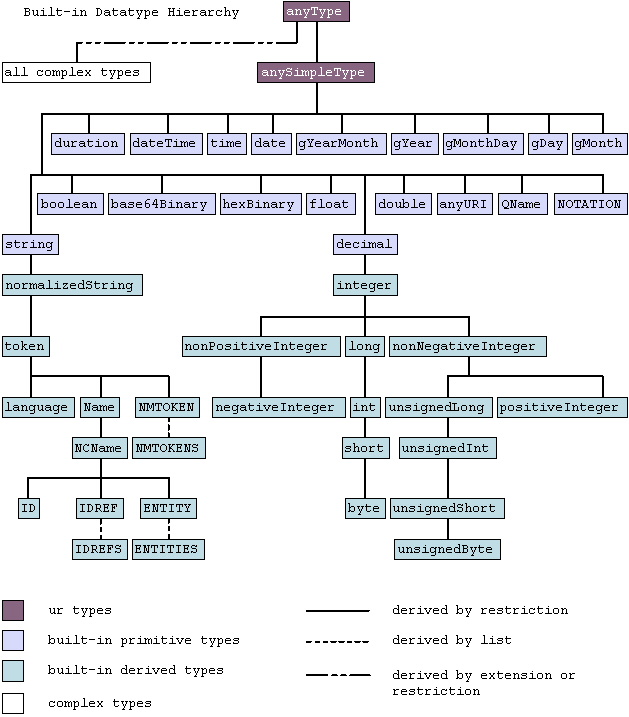
The primitive datatypes
duration, dateTime, time,
date, gYearMonth, gMonthDay,
gDay, gMonth and gYear
use lexical formats inspired by
[ISO 8601]. This appendix provides more detail on the ISO
formats and discusses some deviations from them for the datatypes
defined in this specification.
[ISO 8601] "specifies the representation of dates in the
proleptic Gregorian calendar and times and representations of periods of time".
The proleptic Gregorian calendar includes dates prior to 1582 (the year it came
into use as an ecclesiastical calendar).
It should be pointed out that the datatypes described in this
specification do not cover all the types of data covered by
[ISO 8601], nor do they support all the lexical
representations for those types of data.
[ISO 8601] lexical formats are described using "pictures"
in which characters are used in place of digits. For the primitive datatypes
dateTime, time,
date, gYearMonth, gMonthDay,
gDay, gMonth and gYear.
these characters have the following meanings:
-
C -- represents a digit used in the thousands and hundreds components,
the "century" component, of the time element "year". Legal values are
from 0 to 9.
-
Y -- represents a digit used in the tens and units components of the time
element "year". Legal values are from 0 to 9.
-
M -- represents a digit used in the time element "month". The two
digits in a MM format can have values from 1 to 12.
-
D -- represents a digit used in the time element "day". The two digits
in a DD format can have values from 1 to 28 if the month value equals 2,
1 to 29 if the month value equals 2 and the year is a leap year, 1 to 30
if the month value equals 4, 6, 9 or 11, and 1 to 31 if the month value
equals 1, 3, 5, 7, 8, 10 or 12.
-
h -- represents a digit used in the time element "hour". The two digits
in a hh format can have values from 0 to 23.
-
m -- represents a digit used in the time element "minute". The two digits
in a mm format can have values from 0 to 59.
-
s -- represents a digit used in the time element "second". The two
digits in a ss format can have values from 0 to 60. In the formats
described in this specification the whole number of seconds may
be followed by decimal seconds to an arbitrary level of precision.
This is represented in the picture by "ss.sss". A value of 60 or more is
allowed only in the case of leap seconds. Strictly speaking, a value of
60 or more is not sensible unless the month and day could
represent March 31, June 30, September 30, or December 31 in UTC.
Because the leap second is added or subtracted as the last second of the day
in UTC time, the long (or short) minute could occur at other times in local
time. In cases where the leap second is used with an inappropriate month
and day it, and any fractional seconds, should considered as added or
subtracted from the following minute.
For all the information items indicated by the above characters, leading
zeros are required where indicated.
In addition to the above, certain characters are used as designators
and appear as themselves in lexical formats.
-
T -- is used as time designator to indicate the start of the
representation of the time of day in dateTime.
-
Z -- is used as time-zone designator, immediately (without a space)
following a data element expressing the time of day in Coordinated
Universal Time (UTC) in
dateTime, time,
date, gYearMonth, gMonthDay,
gDay, gMonth, and gYear.
In the lexical format for duration the following
characters are also used as designators and appear as themselves in
lexical formats:
- P -- is used as the time duration designator, preceding a data element
representing a given duration of time.
- Y -- follows the number of years in a time duration.
- M -- follows the number of months or minutes in a time duration.
- D -- follows the number of days in a time duration.
- H -- follows the number of hours in a time duration.
- S -- follows the number of seconds in a time duration.
The values of the
Year, Month, Day, Hour and Minutes components are not restricted but
allow an arbitrary integer. Similarly, the value of the Seconds component
allows an arbitrary decimal. Thus, the lexical format for
duration and datatypes derived from it
does not follow the alternative
format of § 5.5.3.2.1 of [ISO 8601].
D.2 Truncated and Reduced Formats
[ISO 8601] supports a variety of "truncated" formats in
which some of the characters on the left of specific formats, for example,
the
century, can be omitted.
Truncated formats are, in
general, not permitted for the datatypes defined in this specification
with three exceptions. The time datatype uses
a truncated format for dateTime
which represents an instant of time that recurs every day.
Similarly, the gMonthDay and gDay
datatypes use left-truncated formats for date.
The datatype gMonth uses a right and left truncated format for
date.
[ISO 8601] also supports a variety of "reduced" or right-truncated
formats in which some of the characters to the right of specific formats,
such as the
time specification, can be omitted. Right truncated formats are also, in
general,
not permitted for the datatypes defined in this specification
with the following exceptions:
right-truncated representations of dateTime are used as
lexical representations for date, gMonth,
gYear.
D.3 Deviations from ISO 8601 Formats
D.3.1 Sign Allowed
An optional minus sign is allowed immediately preceding, without a space,
the lexical representations for duration, dateTime,
date, gMonth, gYear.
D.3.2 No Year Zero
The year "0000" is an illegal year value.
E Adding durations to dateTimes
Given a dateTime (§3.2.7) S and a duration (§3.2.6)
D, this appendix specifies how to compute
a dateTime (§3.2.7) E where E is the end of the
time period with start S and duration D i.e.
E = S + D. Such computations are used, for example,
to determine whether a dateTime (§3.2.7) is within a specific
time period. This appendix also addresses the addition of duration (§3.2.6)s
to the datatypes date (§3.2.9), gMonth (§3.2.14) and
gYear (§3.2.11) which can be viewed as a set of dateTime (§3.2.7)s.
In such cases, the addition is made to the first or starting
dateTime (§3.2.7) in the set.
This is a logical explanation of the process.
Actual implementations are free to optimize as long as they produce the same
results. The calculation uses the notation S[year] to represent the year
field of S, S[month] to represent the month field, and so on. It also depends on
the following functions:
-
fQuotient(a, b) = the greatest integer less than or equal to a/b
- fQuotient(-1,3) = -1
- fQuotient(0,3)...fQuotient(2,3) = 0
- fQuotient(3,3) = 1
- fQuotient(3.123,3) = 1
-
modulo(a, b) = a - fQuotient(a,b)*b
- modulo(-1,3) = 2
- modulo(0,3)...modulo(2,3) = 0...2
- modulo(3,3) = 0
- modulo(3.123,3) = 0.123
-
fQuotient(a, low, high) = fQuotient(a - low, high - low)
- fQuotient(0, 1, 13) = -1
- fQuotient(1, 1, 13) ... fQuotient(12, 1, 13) = 0
- fQuotient(13, 1, 13) = 1
- fQuotient(13.123, 1, 13) = 1
-
modulo(a, low, high) = modulo(a - low, high - low) + low
- modulo(0, 1, 13) = 12
- modulo(1, 1, 13) ... modulo(12, 1, 13) = 1...12
- modulo(13, 1, 13) = 1
- modulo(13.123, 1, 13) = 1.123
-
maximumDayInMonthFor(yearValue, monthValue) =
- M := modulo(monthValue, 1, 13)
- Y := yearValue + fQuotient(monthValue, 1, 13)
- Return a value based on M and Y:
| 31 | M = January, March, May, July, August, October, or
December |
| 30 | M = April, June, September, or November |
| 29 | M = February AND (modulo(Y, 400) = 0 OR
(modulo(Y, 100) != 0) AND modulo(Y, 4) = 0) |
| 28 | Otherwise |
E.1 Algorithm
Essentially, this calculation is equivalent to separating D into <year,month>
and <day,hour,minute,second> fields. The <year,month> is added to S.
If the day is out of range, it is pinned to be within range. Thus April
31 turns into April 30. Then the <day,hour,minute,second> is added. This
latter addition can cause the year and month to change.
Leap seconds are handled by the computation by treating them as overflows.
Essentially, a value of 60
seconds in S is treated as if it were a duration of 60 seconds added to S
(with a zero seconds field). All calculations
thereafter use 60 seconds per minute.
Thus the addition of either PT1M or PT60S to any dateTime will always
produce the same result. This is a special definition of addition which
is designed to match common practice, and -- most importantly -- be stable
over time.
A definition that attempted to take leap-seconds into account would need to
be constantly updated, and could not predict the results of future
implementation's additions. The decision to introduce a leap second in UTC
is the responsibility of the [International Earth Rotation Service (IERS)]. They make periodic
announcements as to when
leap seconds are to be added, but this is not known more than a year in
advance. For more information on leap seconds, see [U.S. Naval Observatory Time Service Department].
The following is the precise specification. These steps must be followed in
the same order. If a field in D is not specified, it is treated as if it were
zero. If a field in S is not specified, it is treated in the calculation as if
it were the minimum allowed value in that field, however, after the calculation
is concluded, the corresponding field in E is removed (set to unspecified).
Examples:
| dateTime | duration | result |
| 2000-01-12T12:13:14Z | P1Y3M5DT7H10M3.3S | 2001-04-17T19:23:17.3Z |
| 2000-01 | -P3M | 1999-10 |
| 2000-01-12 | PT33H | 2000-01-13 |
E.2 Commutativity and Associativity
Time durations are added by simply adding each of their fields, respectively, without overflow.
The order of addition of durations to instants is significant.
For example, there are cases where:
((dateTime + duration1) + duration2) != ((dateTime +
duration2) + duration1)
Example:
(2000-03-30 + P1D) + P1M = 2000-03-31 + P1M = 2001-04-30
(2000-03-30 + P1M) + P1D = 2000-04-30 + P1D = 2000-05-01
F Regular Expressions
A regular expression R is a sequence of
characters that denote a set of strings L(R).
When used to constrain a lexical space, a
regular expression R asserts that only strings
in L(R) are valid literals for values of that type.
[Definition:] A
regular expression is composed from zero or more
branches, separated by | characters.
|
For all branches S, and for all
regular expressions T, valid
regular expressions R are:
|
Denoting the set of strings L(R) containing:
|
| (empty string) | the set containing just the empty string
|
| S | all strings in L(S) |
| S|T | all strings in L(S) and
all strings in L(T) |
[Definition:] A branch consists
of zero or more pieces, concatenated together.
|
For all pieces S, and for all
branches T, valid
branches R are:
|
Denoting the set of strings L(R) containing:
|
| S | all strings in L(S) |
| ST | all strings st with s in
L(S) and t in L(T) |
[Definition:] A piece is an
atom, possibly followed by a
quantifier.
|
For all atoms S and non-negative
integers n, m such that
n <= m, valid pieces
R are:
|
Denoting the set of strings L(R) containing:
|
| S | all strings in L(S) |
| S? | the empty string, and all strings in
L(S). |
| S* |
All strings in L(S?) and all strings st
with s in L(S*)
and t in L(S). ( all concatenations
of zero or more strings from L(S) ) |
| S+ |
All strings st with s in L(S)
and t in L(S*). ( all concatenations
of one or more strings from L(S) ) |
| S{n,m} |
All strings st with s in L(S)
and t in L(S{n-1,m-1}). ( All
sequences of at least n, and at most m, strings from L(S) ) |
| S{n} |
All strings in L(S{n,n}). ( All
sequences of exactly n strings from L(S) ) |
| S{n,} |
All strings in L(S{n}S*) ( All
sequences of at least n, strings from L(S) ) |
| S{0,m} |
All strings st with s in L(S?)
and t in L(S{0,m-1}). ( All
sequences of at most m, strings from L(S) ) |
| S{0,0} |
The set containing only the empty string
|
NOTE:
The regular expression language in the Perl Programming Language
[Perl] does not include a quantifier of the form
S{,m), since it is logically equivalent to S{0,m}.
We have, therefore, left this logical possibility out of the regular
expression language defined by this specification. We welcome
further input from implementors and schema authors on this issue.
[Definition:] A quantifier
is one of ?, *, +,
{n,m} or {n,}, which have the meanings
defined in the table above.
[Definition:] An atom is either a
normal character, a character class, or
a parenthesized regular expression.
[Definition:] A metacharacter
is either ., \, ?,
*, +, {, }(, ), [ or ].
These characters have special meanings in regular expressions,
but can be escaped to form atoms that denote the
sets of strings containing only themselves, i.e., an escaped
metacharacter behaves like a normal character.
[Definition:] A
normal character is any XML character that is not a
metacharacter. In regular expressions, a normal character is an
atom that denotes the singleton set of strings containing only itself.
| Normal Character |
[10] | Char | ::= | [^.\?*+()|#x5B#x5D] | |
|
Note that a normal character can be represented either as
itself, or with a character
reference.
F.1 Character Classes
[Definition:] A
character class is an atom
R that identifies a set of characters
C(R). The set of strings L(R) denoted by a
character class R contains one single-character string
"c" for each character c in C(R).
A character class is either a character class escape or a
character class expression.
[Definition:] A
character class expression is a character group surrounded
by [ and ] characters. For all character
groups G, [G] is a valid character class
expression, identifying the set of characters
C([G]) = C(G).
| Character Class Expression |
|
|
[Definition:] A
character group is either a positive character group,
a negative character group, or a character class subtraction.
[Definition:]
A positive character group consists of one or more
character ranges or character class escapes, concatenated
together. A positive character group identifies the set of
characters containing all of the characters in all of the sets identified
by its constituent ranges or escapes.
[Definition:]
A negative character group is a
positive character group preceded by the ^ character.
For all positive character groups P, ^P
is a valid negative character group, and C(^P)
contains all XML characters that are not in C(P).
[Definition:] A
character class subtraction is a character class expression
subtracted from a positive character group or
negative character group, using the - character.
| Character Class Subtraction |
|
|
For any positive character group or
negative character group G, and any
character class expression C, G-C is a valid
character class subtraction, identifying the set of all characters in
C(G) that are not also in C(C).
[Definition:] A
character range R identifies a set of
characters C(R) containing all XML characters with UCS
code points in a specified range.
A single XML character is a character range that identifies
the set of characters containing only itself. All XML characters are valid
character ranges, except as follows:
A character range may also be written
in the form s-e, identifying the set that contains all XML characters
with UCS code points greater than or equal to the code point
of s, but not greater than the code point of e.
s-e is a valid character range iff:
NOTE:
The code point of a single character escape is the code point of the
single character in the set of characters that it identifies.
F.1.1 Character Class Escapes
[Definition:]
A character class escape is a short sequence of characters
that identifies predefined character class. The valid character
class escapes are the single character escapes, the
multi-character escapes, and the category escapes (including
the block escapes).
[Definition:] A
single character escape identifies a set containing a only
one character -- usually because that character is difficult or
impossible to write directly into a regular expression.
| Single Character Escape |
[26] | SingleCharEsc | ::= | '\' [nrt\|.?*+(){}#x2D#x5B#x5D#x5E] | |
|
|
The valid single character escapes are:
|
Identifying the set of characters C(R) containing:
|
\n | the newline character (#xA) |
\r | the return character (#xD) |
\t | the tab character (#x9) |
\\ | \ |
\| | | |
\. | . |
\- | - |
\^ | ^ |
\? | ? |
\* | * |
\+ | + |
\{ | { |
\} | } |
\( | ( |
\) | ) |
\[ | [ |
\] | ] |
[Definition:] [Unicode Database] specifies a number of possible
values for the "General Category" property
and provides mappings from code points to specific character properties.
The set containing all characters that have property X,
can be identified with a category escape\p{X}.
The complement of this set is specified with the
category escape\P{X}.
([\P{X}] = [^\p{X}]).
NOTE: [Unicode Database] is subject to future revision. For example, the
mapping from code points to character properties might be updated.
All minimally conforming processors must
support the character properties defined in the version of [Unicode Database]
that is current at the time this specification became a W3C
Recommendation. However, implementors are encouraged to support the
character properties defined in any future version.
The following table specifies the recognized values of the
"General Category" property.
| Category | Property | Meaning |
| Letters | L | All Letters |
| Lu | Uppercase |
| Ll | Lowercase |
| Lt | Titlecase |
| Lm | Modifier |
| Lo | Other |
| |
| Marks | M | All Marks |
| Mn | Non-Spacing |
| Mc | Spacing Combining |
| Me | Enclosing |
| |
| Numbers | N | All Numbers |
| Nd | Decimal Digit |
| Nl | Letter |
| No | Other |
| |
| Punctuation | P | All Punctuation |
| Pc | Connector |
| Pd | Dash |
| Ps | Open |
| Pe | Close |
| Pi | Initial quote
(can behave like Ps or Pe depending on usage) |
| Pf | Final quote
(can behave like Ps or Pe depending on usage) |
| Po | Other |
| |
| Separators | Z | All Separators |
| Zs | Space |
| Zl | Line |
| Zp | Paragraph |
| |
| Symbols | S | All Symbols |
| Sm | Math |
| Sc | Currency |
| Sk | Modifier |
| So | Other |
| |
| Other | C | All Others |
| Cc | Control |
| Cf | Format |
| Co | Private Use |
| Cn | Not Assigned |
| Categories |
[30] | IsCategory | ::= | Letters |
Marks |
Numbers |
Punctuation |
Separators |
Symbols |
Others | |
[31] | Letters | ::= | 'L' [ultmo]? | |
[32] | Marks | ::= | 'M' [nce]? | |
[33] | Numbers | ::= | 'N' [dlo]? | |
[34] | Punctuation | ::= | 'P' [cdseifo]? | |
[35] | Separators | ::= | 'Z' [slp]? | |
[36] | Symbols | ::= | 'S' [mcko]? | |
[37] | Others | ::= | 'C' [cfon]? | |
|
NOTE:
The properties mentioned above exclude the Cs property.
The Cs property identifies "surrogate" characters, which do not
occur at the level of the "character abstraction" that XML instance documents
operate on.
[Definition:] [Unicode Database] groups code points into a number of blocks
such as Basic Latin (i.e., ASCII), Latin-1 Supplement, Hangul Jamo,
CJK Compatibility, etc.
The set containing all characters that have block name X
(with all white space stripped out),
can be identified with a block escape\p{IsX}.
The complement of this set is specified with the
block escape\P{IsX}.
([\P{IsX}] = [^\p{IsX}]).
| Block Escape |
[38] | IsBlock | ::= | 'Is' [a-zA-Z#x2D]+ | |
|
The following table specifies the recognized block names (for more
information, see the "Blocks.txt" file in [Unicode Database]).
| Start Code | End Code | Block Name | | Start Code | End Code | Block Name |
| #x0000 | #x007F | BasicLatin | | #x0080 | #x00FF | Latin-1Supplement |
| #x0100 | #x017F | LatinExtended-A | | #x0180 | #x024F | LatinExtended-B |
| #x0250 | #x02AF | IPAExtensions | | #x02B0 | #x02FF | SpacingModifierLetters |
| #x0300 | #x036F | CombiningDiacriticalMarks | | #x0370 | #x03FF | Greek |
| #x0400 | #x04FF | Cyrillic | | #x0530 | #x058F | Armenian |
| #x0590 | #x05FF | Hebrew | | #x0600 | #x06FF | Arabic |
| #x0700 | #x074F | Syriac | | #x0780 | #x07BF | Thaana |
| #x0900 | #x097F | Devanagari | | #x0980 | #x09FF | Bengali |
| #x0A00 | #x0A7F | Gurmukhi | | #x0A80 | #x0AFF | Gujarati |
| #x0B00 | #x0B7F | Oriya | | #x0B80 | #x0BFF | Tamil |
| #x0C00 | #x0C7F | Telugu | | #x0C80 | #x0CFF | Kannada |
| #x0D00 | #x0D7F | Malayalam | | #x0D80 | #x0DFF | Sinhala |
| #x0E00 | #x0E7F | Thai | | #x0E80 | #x0EFF | Lao |
| #x0F00 | #x0FFF | Tibetan | | #x1000 | #x109F | Myanmar |
| #x10A0 | #x10FF | Georgian | | #x1100 | #x11FF | HangulJamo |
| #x1200 | #x137F | Ethiopic | | #x13A0 | #x13FF | Cherokee |
| #x1400 | #x167F | UnifiedCanadianAboriginalSyllabics | | #x1680 | #x169F | Ogham |
| #x16A0 | #x16FF | Runic | | #x1780 | #x17FF | Khmer |
| #x1800 | #x18AF | Mongolian | | #x1E00 | #x1EFF | LatinExtendedAdditional |
| #x1F00 | #x1FFF | GreekExtended | | #x2000 | #x206F | GeneralPunctuation |
| #x2070 | #x209F | SuperscriptsandSubscripts | | #x20A0 | #x20CF | CurrencySymbols |
| #x20D0 | #x20FF | CombiningMarksforSymbols | | #x2100 | #x214F | LetterlikeSymbols |
| #x2150 | #x218F | NumberForms | | #x2190 | #x21FF | Arrows |
| #x2200 | #x22FF | MathematicalOperators | | #x2300 | #x23FF | MiscellaneousTechnical |
| #x2400 | #x243F | ControlPictures | | #x2440 | #x245F | OpticalCharacterRecognition |
| #x2460 | #x24FF | EnclosedAlphanumerics | | #x2500 | #x257F | BoxDrawing |
| #x2580 | #x259F | BlockElements | | #x25A0 | #x25FF | GeometricShapes |
| #x2600 | #x26FF | MiscellaneousSymbols | | #x2700 | #x27BF | Dingbats |
| #x2800 | #x28FF | BraillePatterns | | #x2E80 | #x2EFF | CJKRadicalsSupplement |
| #x2F00 | #x2FDF | KangxiRadicals | | #x2FF0 | #x2FFF | IdeographicDescriptionCharacters |
| #x3000 | #x303F | CJKSymbolsandPunctuation | | #x3040 | #x309F | Hiragana |
| #x30A0 | #x30FF | Katakana | | #x3100 | #x312F | Bopomofo |
| #x3130 | #x318F | HangulCompatibilityJamo | | #x3190 | #x319F | Kanbun |
| #x31A0 | #x31BF | BopomofoExtended | | #x3200 | #x32FF | EnclosedCJKLettersandMonths |
| #x3300 | #x33FF | CJKCompatibility | | #x3400 | #x4DB5 | CJKUnifiedIdeographsExtensionA |
| #x4E00 | #x9FFF | CJKUnifiedIdeographs | | #xA000 | #xA48F | YiSyllables |
| #xA490 | #xA4CF | YiRadicals | | #xAC00 | #xD7A3 | HangulSyllables |
| #xE000 | #xF8FF | PrivateUse | | #xF900 | #xFAFF | CJKCompatibilityIdeographs |
| #xFB00 | #xFB4F | AlphabeticPresentationForms | | #xFB50 | #xFDFF | ArabicPresentationForms-A |
| #xFE20 | #xFE2F | CombiningHalfMarks | | #xFE30 | #xFE4F | CJKCompatibilityForms |
| #xFE50 | #xFE6F | SmallFormVariants | | #xFE70 | #xFEFE | ArabicPresentationForms-B |
| #xFEFF | #xFEFF | Specials | | #xFF00 | #xFFEF | HalfwidthandFullwidthForms |
| #xFFF0 | #xFFFD | Specials | | | | |
NOTE: [Unicode Database] is subject to future revision.
For example, the
grouping of code points into blocks might be updated.
All minimally conforming processors must
support the blocks defined in the version of [Unicode Database]
that is current at the time this specification became a W3C
Recommendation. However, implementors are encouraged to support the
blocks defined in any future version of the Unicode Standard.
For example, the block escape for identifying the
ASCII characters is \p{IsBasicLatin}.
[Definition:] A
multi-character escape provides a simple way to identify
a commonly used set of characters:
| Multi-Character Escape |
[39] | MultiCharEsc | ::= | '.' | ('\' [sSiIcCdDwW]) | |
|
| Character sequence | Equivalent character class |
| . | [^\n\r] |
| \s | [#x20\t\n\r] |
| \S | [^\s] |
| \i | the set of initial name characters, those
matched by
Letter | '_' | ':' |
| \I | [^\i] |
| \c |
the set of name characters, those
matched by
NameChar |
| \C | [^\c] |
| \d | \p{Nd} |
| \D | [^\d] |
| \w |
[#x0000-#x10FFFF]-[\p{P}\p{S}\p{C}]
(all characters except the set of "punctuation",
"separator" and "control" characters)
|
| \W | [^\w] |
NOTE:
The regular expression language defined here does not
attempt to provide a general solution to "regular expressions" over
UCS character sequences. In particular, it does not easily provide
for matching sequences of base characters and combining marks.
The language is targeted at support of "Level 1" features as defined in
[Unicode Regular Expression Guidelines]. It is hoped that future versions of this
specification will provide support for "Level 2" features.
H Acknowledgements (non-normative)
The following have contributed material to this draft:
- Asir S. Vedamuthu, webMethods, Inc
- Mark Davis, IBM
Co-editor Ashok Malhotra's work on this specification from March 1999 until
February 2001 was supported by IBM.
The editors acknowledge the members of the XML Schema Working Group, the members of other W3C Working Groups, and industry experts in other
forums who have contributed directly or indirectly to the process or content of
creating this document. The Working Group is particularly grateful to Lotus
Development Corp. and IBM for providing teleconferencing facilities.
The current members of the XML Schema Working Group are:
Jim Barnette, Defense Information Systems Agency (DISA); Paul V. Biron, Health Level Seven; Don Box, DevelopMentor; Allen Brown, Microsoft; Lee Buck, TIBCO Extensibility; Charles E. Campbell, Informix; Wayne Carr, Intel; Peter Chen, Bootstrap Alliance and LSU; David Cleary, Progress Software; Dan Connolly, W3C (staff contact); Ugo Corda, Xerox; Roger L. Costello, MITRE; Haavard Danielson, Progress Software; Josef Dietl, Mozquito Technologies; David Ezell, Hewlett Packard Company; Alexander Falk, Altova GmbH; David Fallside, IBM; Dan Fox, Defense Logistics Information Service (DLIS); Matthew Fuchs, Commerce One; Andrew Goodchild, Distributed Systems Technology Centre (DSTC Pty Ltd); Paul Grosso, ArborText, Inc; Martin Gudgin, DevelopMentor; Dave Hollander, Contivo, Inc (co-chair); Mary Holstege, Invited Expert; Jane Hunter, Distributed Systems Technology Centre (DSTC Pty Ltd); Rick Jelliffe, Academia Sinica; Simon Johnston, Rational Software; Bob Lojek, Mozquito Technologies; Ashok Malhotra, Microsoft; Lisa Martin, IBM; Noah Mendelsohn, Lotus Development Corporation; Adrian Michel, Commerce One; Alex Milowski, Invited Expert; Don Mullen, TIBCO Extensibility; Dave Peterson, Graphic Communications Association; Jonathan Robie, Software AG; Eric Sedlar, Oracle Corp.; C. M. Sperberg-McQueen, W3C (co-chair); Bob Streich, Calico Commerce; William K. Stumbo, Xerox; Henry S. Thompson, University of Edinburgh; Mark Tucker, Health Level Seven; Asir S. Vedamuthu, webMethods, Inc; Priscilla Walmsley, XMLSolutions; Norm Walsh, Sun Microsystems; Aki Yoshida, SAP AG; Kongyi Zhou, Oracle Corp.
The XML Schema Working Group has benefited in its work from the
participation and contributions of a number of people not currently
members of the Working Group, including
in particular those named below. Affiliations given are those current at
the time of their work with the WG.
Paula Angerstein, Vignette Corporation; David Beech, Oracle Corp.; Gabe Beged-Dov, Rogue Wave Software; Greg Bumgardner, Rogue Wave Software; Dean Burson, Lotus Development Corporation; Mike Cokus, MITRE; Andrew Eisenberg, Progress Software; Rob Ellman, Calico Commerce; George Feinberg, Object Design; Charles Frankston, Microsoft; Ernesto Guerrieri, Inso; Michael Hyman, Microsoft; Renato Iannella, Distributed Systems Technology Centre (DSTC Pty Ltd); Dianne Kennedy, Graphic Communications Association; Janet Koenig, Sun Microsystems; Setrag Khoshafian, Technology Deployment International (TDI); Ara Kullukian, Technology Deployment International (TDI); Andrew Layman, Microsoft; Dmitry Lenkov, Hewlett Packard Company; John McCarthy, Lawrence Berkeley National Laboratory; Murata Makoto, Xerox; Eve Maler, Sun Microsystems; Murray Maloney, Muzmo Communication, acting for Commerce One; Chris Olds, Wall Data; Frank Olken, Lawrence Berkeley National Laboratory; Shriram Revankar, Xerox; Mark Reinhold, Sun Microsystems; John C. Schneider, MITRE; Lew Shannon, NCR; William Shea, Merrill Lynch; Ralph Swick, W3C; Tony Stewart, Rivcom; Matt Timmermans, Microstar; Jim Trezzo, Oracle Corp.; Steph Tryphonas, Microstar